|
I am a Research Scientist at fal.ai, working on generative AI and diffusion models. I completed my PhD at Koç University under the supervision of Prof. Yücel Yemez, focusing on object-centric learning and compositional image and video generation (PhD Thesis). Previously, I received my Master's degree (Thesis) from Koç University and my Bachelor's from Middle East Technical University. Recipient of the Academic Excellence Award at Koç University. Email / CV / Google Scholar / GitHub / LinkedIn / X (Twitter) |

|
|
I'm interested in computer vision, machine learning, with a special interest in object-centric learning and generative models. |
|
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, Pinar Yanardag arXiv preprint, 2025 Preprint / Project Website / bibtex ∞-RoPE enables infinite-horizon, action-controllable video generation through Block-Relativistic RoPE, KV Flush, and RoPE Cut—training-free techniques that overcome temporal horizon limits, enable fine-grained action control, and support cinematic scene transitions within a single autoregressive rollout. |
|

|
Adil Kaan Akan, Yücel Yemez Under Review at IEEE TPAMI Preprint / Project Website / bibtex We extend SlotAdapt to video by learning temporally consistent object-centric slots and conditioning them on pretrained diffusion models for compositional video synthesis. Our approach enables intuitive editing capabilities like object insertion, deletion, or replacement while maintaining consistent identities across frames. Experiments demonstrate superior video generation quality and temporal consistency, uniquely integrating segmentation with robust generative performance. |

|
Adil Kaan Akan, Yücel Yemez ICLR 2025 Preprint / Project Website / bibtex SlotAdapt combines slot attention with pretrained diffusion models through adapters for slot-based conditioning. By adding a guidance loss to align cross-attention with slot attention, our model better identifies objects without external supervision. Experiments show superior performance in object discovery and image generation, particularly on complex real-world images. |
|
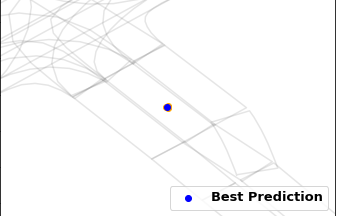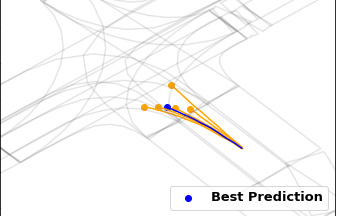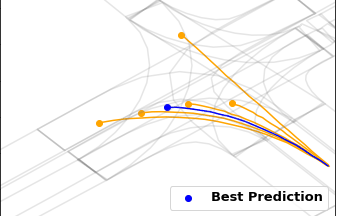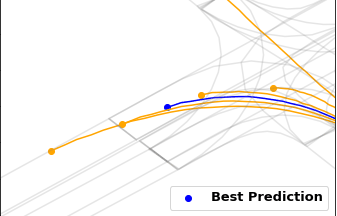
Gorkay Aydemir, Adil Kaan Akan, Fatma Guney ICCV 2023 Preprint / Project Website / Code / bibtex We propose a novel method for trajectory prediction that can adapt itself into every agent in the shared scene. We exploit dynamic weight learning to adapt each agent's state separately to predict their future trajectories simultaneously without rotating and normalizing the scene frame. Our results achieve state-of-the-art performance on Argoverse and INTERACTION datasets with impressive runtime performance. |
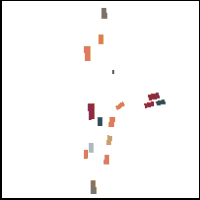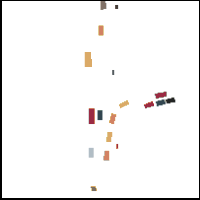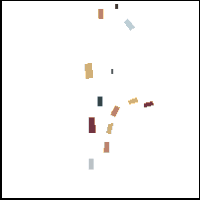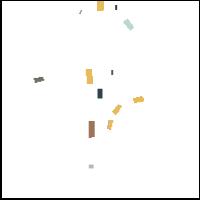
|
Adil Kaan Akan, Fatma Guney ECCV 2022 Preprint / Project Website / Code / bibtex We propose a novel method for future instance segmentation in Bird's-eye view space. We exploit state-space models for the future state prediction for encoding 3D scene structure and decoding future instance segmentations. Our results achieve state-of-the-art performance on NuScenes dataset with a great margin. |
|
Gorkay Aydemir, Adil Kaan Akan, Fatma Guney arXiv preprint Preprint / Project Website / Code / bibtex We propose a novel method for trajectory prediction. We propose to use Temporal Graph Networks for learning dynamically evolving agent features. Our results reaches the state-of-the-art performance on Argoverse Forecasting dataset. |

|
Adil Kaan Akan, Sadra Safadoust, Fatma Guney arXiv preprint Preprint / bibtex We decompose the scene into static and dynamic parts by encoding it into ego-motion and optical flow. We first factorize scene structure, the ego-motion, then conditioned on this, we predict the residual flow in the scene specifically for independently moving objects. |
|
Adil Kaan Akan, Erkut Erdem, Aykut Erdem, Fatma Guney ICCV 2021 Preprint / Project Website / Code / bibtex We propose a novel way for stochastic video prediction by decomposing static and dynamic parts of the scene. We reason about appearance and motion in the video stochastically by predicting the future based on the motion history. |

|
Adil Kaan Akan, Emre Akbas, Fatos T. Yarman-Vural Signal, Image and Video Processing Preprint / bibtex We propose theoretical understanding of JND concept for machine perception and conduct further analyses and comparisons with other state-of-the-art methods. This paper extends our ICIP 2020 paper. |

|
Adil Kaan Akan, Mehmet Ali Genc, Fatos T. Yarman-Vural ICIP 2020 Preprint / bibtex We propose a new concept for adversarial example generation. Inspired by the experimental psychology, we use the concept of Just Noticeable Difference to generate natural looking adversarial images. |
|
|
|
Website format from Jon Barron. |